人脸识别
- 1、学会使用 PCA 主成分分析法。
- 2、初步了解人脸识别的特征法。
- 3、更熟练地掌握 matlab 的使用。
PCA(主成分分析法介绍)
PCA 方法的基本原理是:利用离散 K-L 变换提取人脸的主要成分,构成特征脸空间,识别时把测试样本投影到该空间,构成一组投影系数,通过与特征脸的距离比较,距离最小的特征脸对应的即是识别结果。 基于 PCA 的人脸识别分为三个阶段,第一个阶段利用训练样本集构建特征脸空间;第二个阶段是训练阶段,主要是将训练图像投影到特征脸子空间上;第三个阶段是识别阶段,将测试样本集投影到特征脸子空间,然后与投影后的训练图像相比较,距离最小的为识别结果。 基于 PCA 的人脸识别其实一种统计性的模板比配方法,原理简单,易于实现,但也有不足,它的识别率会随着关照,人脸角度,训练样本集的数量而变换,但仍不失为一种比较好的方法。
实验步骤
实验1:(测试时所识别的个体出现在训练库中)
1.1、重新组织训练集、测试集
% 测试时所识别的个体出现在训练库中
clear, clc;
TRAIN_DATA_PATH = 'train';
TEST_DATA_PATH = 'test';
per_data_num = 10;
train_data_num = 5;
test_data_num = per_data_num - train_data_num;
GetTrainTestData(TRAIN_DATA_PATH, TEST_DATA_PATH, train_data_num);
- 关键函数
function [] = GetTrainTestData(TRAIN_DATA_PATH, TEST_DATA_PATH, train_num)
if exist(TEST_DATA_PATH, 'dir')
rmdir(TEST_DATA_PATH, 's')
end
if exist(TRAIN_DATA_PATH, 'dir')
rmdir(TRAIN_DATA_PATH, 's');
end
mkdir(TEST_DATA_PATH);
mkdir(TRAIN_DATA_PATH);
n = 1;
p=1;
for i=1:40
a=1:10;
Ind = a(:,randperm(size(a,2)));
for h = 1:train_num
j= Ind(1,h);
File=['orl_faces\s',sprintf('%d',i),'\',sprintf('%d',j),'.pgm'];
Filesave=[TRAIN_DATA_PATH,'\',sprintf('%03d',n),'.pgm'];
copyfile(File,Filesave)
n = n + 1;
end
for h = train_num+1:10
j= Ind(1,h);
File=['orl_faces\s',sprintf('%d',i),'\',sprintf('%d',j),'.pgm'];
Filesave=[TEST_DATA_PATH,'\',sprintf('%03d',p),'.pgm'];
copyfile(File,Filesave)
p = p + 1;
end
end
End
- 说明:该部分的实现可以将原始人脸数据集按照我们的要求重新划分为训练集与测试集。这里我们采用的规则是每个人的人脸数据集取5张作为训练集、5张作为测试集。
训练模型
[ImageSize, wts, image, img_pj, W, V] = TrainData(TRAIN_DATA_PATH);
% 显示特征脸 平均脸
EFNum = 5;
figure;
subplot(2, 3, 1);
imshow(reshape(uint8(img_pj), ImageSize));title('平均脸');
for i=1:EFNum
subplot(2,3,i+1);
imshow(reshape(uint8(V(:,i)), ImageSize));
title(sprintf('特征脸 %d', i));
end
- 关键函数
function [ImgSize, wts, image, img_pj, W, V] = TrainData(path)
% 批量读取指定文件夹下的图片
img_path = dir(strcat(path,'\*.pgm'));
img_num = length(img_path);
imagedata = [];
ImgSize = [];
if img_num >0
for j = 1:img_num
img_name = img_path(j).name;
temp = imread(strcat(path, '/', img_name));
if j == 1
ImgSize = size(temp);
end
temp = reshape(double(temp), [], 1);
% temp = double(temp(:));
imagedata = [imagedata, temp];
end
end
wts = size(imagedata,2);
image = imagedata;
% 中心化并计算协方差矩阵
img_pj = mean(imagedata,2);
for i = 1:wts
imagedata(:,i) = imagedata(:,i) - img_pj;
end
covMat = imagedata'*imagedata;
% PCA 降维
[COEFF, latent, explained] = pcacov(covMat);
% 选择构成 95%能量的特征值
i = 1;
proportion = 0;
while(proportion < 95)
proportion = proportion + explained(i);
i = i+1;
end
k = i - 1;
%求出原协方差矩阵的特征向量,即特征脸
V = imagedata*COEFF; % N*M 阶
V = V(:,1:k);
% 训练样本在 PCA 特征空间下的表达矩阵 k*M
W = V'*imagedata;
% msgbox(['训练完成'])
End
-
中间结果

-
在该部分中,我们基于PCA方法获得了训练集的特征空间,并显示出了前五张特征脸以及平均脸。
使用测试集测试模型
percentage = TestData(TEST_DATA_PATH, train_data_num, test_data_num , wts, ImageSize, image, img_pj, W, V, true);
fprintf('准确率 %.2f %%\n', percentage);
- 关键函数
function [ percentage ] = TestData(path, train_data_num, test_data_num , wts, ImgSize, image, img_pj, W, V, flag)
% 测试样本
img_path = dir(strcat(path,'\*.pgm'));
img_num = length(img_path);
right_num = 0;
if flag
figure;
end
if img_num >0
for j = 1:img_num
img_name = img_path(j).name;
im=imread(strcat(path, '/', img_name));
im = double(reshape(im, [], 1));
objectone = V'*(im - img_pj);
distance = zeros(wts,1);
for k = 1:wts
distance(k) = norm(objectone - W(:,k));
end
[s_temp,id]=sort(distance,'ascend');
if floor((j-1)/test_data_num) == floor((id(1)-1)/train_data_num)
right_num = right_num + 1;
fprintf('%d 匹配成功\n', j);
else
fprintf('%d 匹配失败\n', j);
end
if flag
subplot(2,2,1),imshow(reshape(uint8(im),ImgSize));title('测试图片');
subplot(2,2,2),imshow(reshape(uint8(image(:, id(1))), ImgSize));title('第1匹配度');
subplot(2,2,3),imshow(reshape(uint8(image(:, id(2))), ImgSize));title('第2匹配度');
subplot(2,2,4),imshow(reshape(uint8(image(:, id(3))), ImgSize));title('第3匹配度');
pause(0.01);
end
end
end
percentage = right_num / img_num * 100;
end
- 中间识别结果

识别成功率影响因素探究
nums = [1:1:9];
p = [];
for i=1:size(nums, 2)
train_data_num = nums(i);
test_data_num = per_data_num - train_data_num;
GetTrainTestData(TRAIN_DATA_PATH, TEST_DATA_PATH, train_data_num);
[ImageSize, wts, image, img_pj, W, V] = TrainData(TRAIN_DATA_PATH);
percentage = TestData(TEST_DATA_PATH, train_data_num, test_data_num , wts, ImageSize, image, img_pj, W, V, false);
p = [p, percentage];
fprintf('准确率 %.2f %%\n', percentage);
end
figure,plot(nums, p, '.-', 'markerSize', 15);
title('训练集数量对识别正确率的影响');
xlabel('训练集张数/人');ylabel('正确率/百分比');
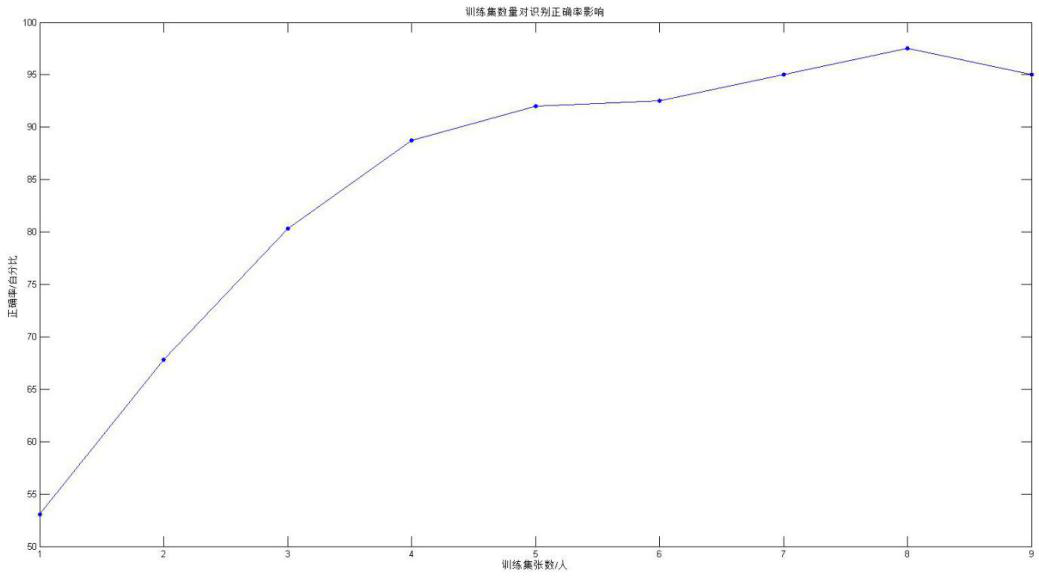
- 在该部分实验中,我探究了训练集的数量对识别成功率的影响。在每次训练过程开始前,我从人脸数据集中每人选取的训练图片数量为1/2/3/…/9,而测试图片数量则为9/8/7/…/1。然后,进行模型训练、识别过程。经过9次实验,得到了在不同训练集数量的情况下,不同的识别率。观察上图发现,随着训练集数量的增加,识别正确率也在增加。不过,在达到一定的训练集规模后,识别正确率趋于稳定。
实验2:(测试时所识别的个体未出现在训练库中)
重新组织训练集、测试集
% 测试时所识别个体未出现在训练库中
clear;
clc;
TRAIN_NUM = 30; % 训练集人数
TEST_NUM = 10; % 测试集人数
TEST_ImTempNum = 5; % 测试集模板数
TEST_ImTestNum = 5; % 测试集待识别数
per_data_num = 10; % 每个人的人脸图数量
train_data_num = 5; % 用于样本集的数量
test_data_num = per_data_num - train_data_num; % 用于待识别的图片数量
ROOT_PATH = 'orl_faces'; % 人脸数据集
TRAIN_DATA_PATH = 'p2_train'; % 训练集
TEST_DATA_TEMP_PATH = 'p2_test_temp'; % 测试样本集
TEST_DATA_PATH = 'p2_test'; % 测试待识别集
if ~exist(TRAIN_DATA_PATH, 'dir')
mkdir(TRAIN_DATA_PATH);
end
if ~exist(TEST_DATA_TEMP_PATH, 'dir')
mkdir(TEST_DATA_TEMP_PATH);
end
if ~exist(TEST_DATA_PATH)
mkdir(TEST_DATA_PATH);
end
n = 1;
for i=1:TRAIN_NUM
dirname = sprintf('%s\\s%d', ROOT_PATH, i);
for j=1:per_data_num
File = sprintf('%s\\%d.pgm', dirname, j);
Filesave=[TRAIN_DATA_PATH,'\',sprintf('%03d',n),'.pgm'];
copyfile(File,Filesave)
n = n + 1;
end
end
n = 1;
p = 1;
for i=TRAIN_NUM+1:TRAIN_NUM+TEST_NUM
dirname = sprintf('%s\\s%d', ROOT_PATH, i);
for j=1:train_data_num
File = sprintf('%s\\%d.pgm', dirname, j);
Filesave=[TEST_DATA_TEMP_PATH,'\',sprintf('%03d',n),'.pgm'];
copyfile(File,Filesave)
n = n + 1;
end
for j=train_data_num+1:per_data_num
File = sprintf('%s\\%d.pgm', dirname, j);
Filesave=[TEST_DATA_PATH,'\',sprintf('%03d',p),'.pgm'];
copyfile(File,Filesave)
p = p + 1;
end
end
- 在该部分实验中,我们将采用测试时所识别个体未出现在训练库中。因此,我们选择30个人的人脸图片为训练集,而其余10个人的人脸图片为测试集。而测试集中,每个人的5张图片为测试样本图片,5张图片为待识别图片。
训练模型
% 训练PCA模型
[ImgSize, wts, image, img_pj, W, V] = TrainData(TRAIN_DATA_PATH);
% 显示特征脸 平均脸
EFNum = 5;
figure;
subplot(2, 3, 1);
imshow(reshape(uint8(img_pj), ImgSize));title('平均脸');
for i=1:EFNum
subplot(2,3,i+1);
imshow(reshape(uint8(V(:,i)), ImgSize));
title(sprintf('特征脸 %d', i));
End
- 中间结果

使用测试集测试模型
% 读取测试样本集
img_path = dir(strcat(TEST_DATA_TEMP_PATH,'\*.pgm'));
img_num = length(img_path);
image = [];
imagedata = [];
if img_num >0
for j = 1:img_num
img_name = img_path(j).name;
temp = imread(strcat(TEST_DATA_TEMP_PATH, '/', img_name));
temp = reshape(double(temp), [], 1);
image = [image, temp];
temp = temp - img_pj;
imagedata = [imagedata, temp];
end
end
wts = size(imagedata,2);
% 将测试样本集投影至特征脸空间
W = V' * imagedata;
percentage = TestData(TEST_DATA_PATH, train_data_num, test_data_num ...
, wts, ImgSize, image, img_pj, W, V, true);
fprintf('准确率 %.2f %%\n', percentage);
- 中间结果

- 在该部分实验中,我们采用测试时所识别的个体未出现在训练库中的方式来进行实验。通过上面的结果,在选取30人为训练集,10人为测试集,其中测试集的5张为测试样本,5张为待识别图片的情况下,识别正确率达到90%,与实验1(测试时所识别的个体出现在训练库中)所得的正确率93%较为接近。
总结
- 在本次实验中,我们基于PCA进行人脸识别。整个实验分为两部分,一部分为:测试时所识别的个体出现在训练库中的情况,另一部分为:测试时所识别的个体未出现在训练库中的情况。
- 在实验1(测试时所识别的个体出现在训练库里)中,我们针对不同的训练集数量进行了测试,并得出在相应情况下的识别正确率。由图表分析可以看出,随着训练集数量的上升,识别正确率也在提高。而当训练集数量达到一定规模后,识别正确率稳定在一个范围内。
- 在实验2(测试时所识别的个体未出现在训练库里)中,我们进行了人脸识别正确率的考查。在选取30人为训练集,10人为测试集,其中测试集的5张为测试样本,5张为待识别图片的情况下,识别正确率达到90%,与实验1所得的正确率93%较为接近。